요즘 누가 머신러닝을 코드로 돌려?
- 종호 박
- 2024년 4월 1일
- 3분 분량
요즘 누가 머신러닝을 코드로 돌려? : SageMaker Canvas에서 클릭 한 번으로 AI모델 튜닝하고 훈련까지

Written by Hyejin Jeon
안녕하세요, 스마일샤크의 전혜진입니다.
일반적으로 머신 러닝 모델을 개발하는 데는 데이터 준비부터 모델 개발, 모델 배포까지 수개월의 시간이 소요됩니다. 이 과정에는 모델 종류 선택, 학습 기법 결정, 코드 작성 등 머신 러닝에 대한 깊은 전문 지식이 요구됩니다.
SageMaker Canvas는 이러한 어려움을 극복하기 위해 등장한 서비스인데요, AI에 대한 전문지식이나 코드 작성 능력이 없어도 머신 러닝 모델을 쉽게 개발하고 정확한 예측을 생성할 수 있습니다.
회사가 소유한 자체 데이터셋을 사용하여 모델을 학습시키고, 원하는 타겟을 지정해 예측을 수행할 수 있는데요, 이를 통해 판매량을 예측하거나 수요를 분석하고 마케팅 컨텐츠를 생성하거나 필요한 정보만 추출하는 등 다양한 목적으로 사용할 수 있습니다.
그러면 SageMakerCanvas에서 Claude, Falcon과 같은 파운데이션 모델을 튜닝하고 ,사용자 지정 모델의 데이터를 쉽게 가공하고 빌드하는 실습을 진행해 보겠습니다. 이 모든 과정은 코드 작성 없이 진행되므로 부담없이 참여하실 수 있습니다!
💡 주의! 리소스 사용량 및 비용에 대한 책임은 사용자에게 있습니다.사전 세팅은 아래 내용을 참고해주세요.
VPC 엔드포인트 설정

인터넷 액세스 없이 VPC 내에서 SageMaker Canvas와 다른 서비스들 간의 액세스를 허용해야 합니다. 다음과 같은 서비스들의 VPC 엔드포인트를 생성해주세요.
com.amazonaws.Region.sagemaker.api
com.amazonaws.Region.sagemaker.runtime
com.amazonaws.Region.forecast
com.amazonaws.Region.forecastquery
SageMaker 도메인 설정
① 조직용 설정을 선택합니다.

② 도메인 이름을 입력하고 IAM 사용자를 생성합니다. 그외의 설정은 기본값으로 설정한 뒤 생성할 S3 버킷 이름을 입력해주세요.

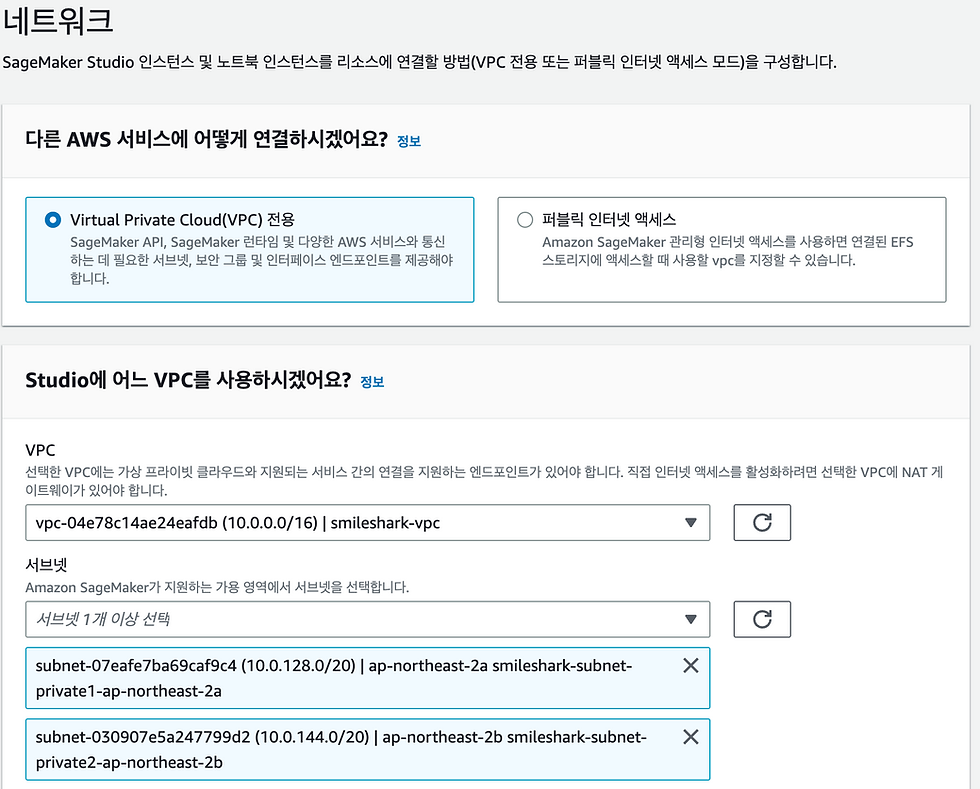
③ 네트워크는 인터넷 액세스가 아닌 VPC 전용으로 선택합니다.
참고로 퍼블릭 VPC 서브넷에서 NAT 게이트웨이를 사용하여 프라이빗 서브넷의 아웃바운드 트래픽이 활성화되어 있어야 합니다.
IAM 역할 설정
생성된 SageMaker Canvas 역할인 SageMaker-ExecutionRole의 신뢰 관계를 다음과 같이 설정합니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"forecast.amazonaws.com",
"sagemaker.amazonaws.com",
"bedrock.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
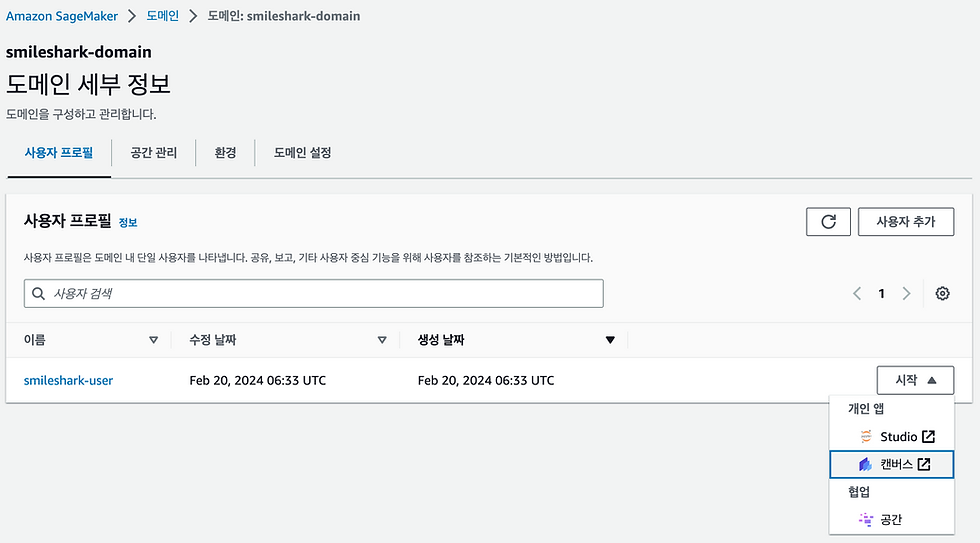
}SageMaker Canvas의 도메인이 생성되었으면 이제 사용자 프로필에서 시작 버튼을 눌러 캔버스를 시작할 수 있습니다.
데이터셋 준비
1. 데이터셋 S3 업로드
아래 링크를 통해 3개의 데이터 세트를 다운받아 주시고 S3 버킷에 업로드해주세요.
Q&A 데이터셋
배송 로그
배송 제품 설명
2. 데이터셋 생성하기
Data Wragler 메뉴에서 Create - Tabular를 누른 후 데이터 세트 이름을 입력해 줍니다.

3. S3 버킷에서 데이터셋 가져오기
S3 버킷에 업로드한 데이터세트를 선택하고 Create dataset을 눌러주세요.

파운데이션 모델 튜닝하기
1. 모델 선택하기
바로 튜닝하기 위해 My models 메뉴를 선택하고 New model을 클릭합니다.
파운데이션 모델을 주택 가격을 예측하는 모델로 튜닝하기 위해 faq-fm-model이라고 명칭을 적고 Fine-tune foundation model을 선택하여 생성해 줍니다.

2. 입출력 데이터 선택하기
데이터 세트(Q&A 데이터셋)를 선택합니다. 여기서 훈련할 모델을 최대 3개까지 선택할 수 있습니다. 입력 열과 출력 열까지 선택한 후 Fine-tune을 클릭하여 훈련을 시작합니다.

3. 모델 분석하기
훈련은 최대 5시간까지 소요되며, 훈련이 완료되면 다양한 지표로 결과를 분석할 수 있습니다.
또한 훈련된 파운데이션 모델과 훈련되지 않은 파운데이션 모델의 답변에 차이가 있는지 비교해 볼 수도 있습니다. Test in Ready-to-user model을 클릭합니다.

4. 훈련된 모델로 테스트하기
오른쪽 상단의 Compare 버튼을 눌러 기본 모델을 선택한 뒤 질문을 하면 두 모델이 각각 다른 답변을 도출합니다.
오른쪽의 기본 모델이 전형적인 답변을 하는 것에 반해, 왼쪽의 튜닝된 모델은 학습한 데이터 세트에 기반해서 답변한다는 것을 확인할 수 있습니다.

사용자 지정 모델 사용하기
1. 데이터 세트 Join
shipping logs와 product descriptions 데이터세트에 공통으로 존재하는 ProductId 컬럼으로 두 데이터 세트를 쉽게 Join 할 수 있습니다. Join data를 클릭합니다.

두 개의 데이터 세트를 각각 오른쪽에 끌어다 놓고 Join 방식으로 Inner를 선택한 뒤 Import 해줍니다.

2. 모델 생성하기
생성된 데이터로 오른쪽 상단의 Create a model을 누르면 모델을 생성할 수 있는데요, 이 과정에서 데이터를 전처리할 수 있습니다.

3. 타겟 및 모델 타입 선택
어떤 타겟을 예측할 것인지 선택해야 하는데요, 배송 예정일을 예측해야 하므로 ExpectedShippingDays를 선택하고 Configure model을 누릅니다.

Configure model에서 모델 유형을 선택할 수 있습니다. Time series forecasting(시계열 예측)은 주식 가격이나 웹사이트 방문자 수 등 시간에 따른 데이터를 예측하는 방식이고, Numeric model type(수치 예측)은 가격 등의 숫자형 데이터를 예측하는 방법이므로 Numeric model type을 선택합니다.

4. 데이터 가공하기
View all을 누르고 Custom formula를 클릭하면 데이터에 수식을 적용할 수 있습니다. 데이터명과 수식을 입력하면 가공된 컬럼을 추가할 수 있습니다.

삭제할 값은 데이터 컬럼의 체크박스를 해제하여 Drop 합니다. 여러 가지 추가적인 변환 방법은 아래 링크를 참고해 주세요. https://docs.aws.amazon.com/ko_kr/sagemaker/latest/dg/canvas-prepare-data.html

5. 모델 빌드하기
Standard build는 Quick build에 비해 모델 생성에 좀 더 오랜 시간이 걸리지만 더 나은 성능의 모델을 생성할 수 있는데요, 빠르게 빌드하기 위해 Quick build를 선택하겠습니다.
빌드된 모델의 Overview, Scoring, Advanced metrics 탭에서 각각 데이터가 예측에 미치는 영향, 오차범위, 그리고 모델의 성능 및 고급 지표를 확인할 수 있습니다.

마무리
이렇게 SageMaker Canvas를 통해 AWS의 파운데이션 모델이나 사용자 지정 모델을 쉽게 훈련하고 배포할 수 있습니다. 그 외에도 SageMaker 엔드포인트에 모델을 배포하여 실시간으로 예측할 수 있고, Amazon QuickSaight와 통합하여 보다 정확한 예측을 대시보드에서 확인하실 수 있습니다.
실제 사례로, 삼성전자는 SageMaker Canvas를 사용하여 PC 배송 수요 예측에 걸리던 시간을 1~2일 이상 되었던 시간을 단 1~2시간으로 단축할 수 있었고, 한 헬스케어 서비스 업체는 여러 의료기관들로부터 수집된 데이터를 표준화하고 통합하는 작업을 수행할 수 있었습니다.
보유하고 있는 데이터에서 어떤 인사이트를 얻을 수 있을지 궁금하신 분들은 SageMaker Canvas를 사용하여 손쉽게 기계학습 예측을 도전해 보세요!




Comentarios