제로 콜라, 제로 맥주 그리고 제로 ETL: DynamoDB와 OpenSearch Zero-ETL로 데이터 변환을 한 번에

Written by Hyejin Jeon
안녕하세요, 스마일샤크의 전혜진입니다.
AWS의 Zero-ETL 기능이 2023년 11월 정식 출시되었습니다. 제로 콜라, 제로 맥주에 이어결국 Zero-ETL도 출시되었네요..
오늘은 Zero-ETL 기능이 무엇인지 살펴보고, 얼마나 편리하고 간단하게 기능을 구현할 수 있는지 직접 실습으로 알아보겠습니다.
Zero-ETL이란
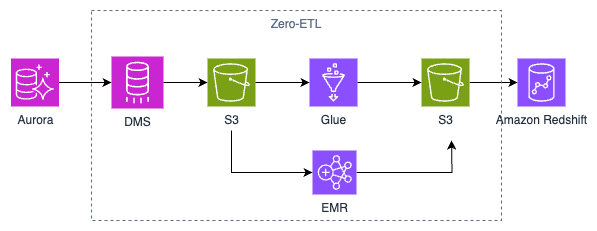
예를 들어, 고객 주문 데이터를 Aurora MySQL 데이터베이스에 저장하고 있습니다.
이 데이터를 분석하여 판매 동향을 파악하고, 재고 관리나 마케팅 전략을 세우기 위해 데이터 웨어하우스 서비스인 Amazon Redshift로 데이터를 옮겨야 하는데요,
기존에는 DMS, Glue와 같은 서비스를 연동하여 데이터를 추출하고 데이터 형식을 변환하고 Redshift에 로드해야 했습니다.
Zero-ETL은 이러한 데이터 처리 파이프라인을 구축하지 않거나 최소화하는 프로세스입니다.
AWS가 데이터 변환 및 로드를 자동으로 관리하여 별도의 ETL 과정이 필요하지 않고 그만큼 데이터를 거의 실시간으로 Redshift로 이동할 수 있습니다.
Zero-ETL을 사용하는 비용은 무료이고, 데이터 필터링이라는 기능을 사용하면 필요한 테이블만 분석할 수 있기 때문에 기존보다 훨씬 비용을 절감할 수 있습니다.
DynamoDB와 OpenSearch의 Zero-ETL
Aurora와 Redshift뿐만 아니라 DynamoDB와 Amazon OpenSearch 간의 Zero-ETL도 가능합니다.
DynamoDB는 완전 관리형 NoSQL 데이터베이스 서비스로 주로 실시간 트랜잭션 데이터를 저장하는 데 사용됩니다.
가격 대비 성능이 좋은 데이터베이스이지만 데이터 검색 쿼리를 제공하지는 않아서 이를 보완하기 위해 OpenSearch 서비스와 연동하여 사용하는데요,
OpenSearch는 Elasticsearch와 호환되는 검색 및 분석 엔진으로 쿼리를 통해 실시간 로그 분석, 모니터링, 웹사이트 검색이 가능합니다.

기존에는 DynamoDB 테이블의 변경 사항을 OpenSearch로 스트리밍하기 위해 AWS Lambda의 로직을 직접 코딩하여 데이터 파이프라인을 설정해야 했습니다.
현재는 OpenSearch Ingestion 파이프라인을 통해 자동화된 데이터 동기화 기능을 사용할 수 있습니다.
두 서비스를 연동해서 DynamoDB의 스트림 데이터를 OpenSearch로 실시간 전송해 보겠습니다.
Zero-ETL 파이프라인 구축 실습
1. 전제 조건
1. S3 버킷 생성
2. OpenSearch 도메인 생성 - 링크 를 참고하여 DynamoDB와 연동할 OpenSearch 도메인을 생성합니다.

3. 다음과 같은 IAM 역할을 생성합니다.
2. DynamoDB 테이블 생성
1. DynamoDB 테이블을 생성합니다. 특정 시점 복구(PITR) 및 DynamoDB 스트림을 활성화합니다.
2. 파이썬을 사용해 ProductCatalog 테이블에 테스트 데이터를 삽입합니다. (아래 파이썬 스크립트를 실행하려면 boto3를 설치하고 AWS CLI 자격증명이 설정되어야 합니다.)
import boto 3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('productCatalog')
def batch_write(items):
with table.batch_writer() as batch:
for item in items:
batch.put_item(Item=item)
items = [
{
"Id": 101,
"도서명": "To Kill a Mockingbird",
"도서번호": "978-0061120084",
"저자": "Harper Lee",
"가격": 12000
},
{
"Id": 102,
"도서명": "1984",
"도서번호": "978-0451524935",
"저자": "George Orwell",
"가격": 15000
},
{
"Id": 103,
"도서명": "The Great Gatsby",
"도서번호": "978-0743273565",
"저자": "F. Scott Fitzgerald",
"가격": 20000
}
]
batch_write(items)3. Zero-ETL 파이프라인 생성
1. DynamoDB - [통합] - ProductCatalog 테이블 선택 - [생성]을 클릭합니다.
![DynamoDB - [통합] - ProductCatalog 테이블 선택 - [생성]](https://static.wixstatic.com/media/3aac70_f0ae5d035eee439c953946abaa34a17a~mv2.png/v1/fill/w_980,h_316,al_c,q_85,usm_0.66_1.00_0.01,enc_avif,quality_auto/3aac70_f0ae5d035eee439c953946abaa34a17a~mv2.png)
2. 제일 중요한 부분은 이 파이프라인 구성 템플릿 작성입니다.
모든 파이프라인 설정은 이 하나의 템플릿을 통해 이루어지는데요, 리소스 ARN 등의 필수값을 입력하고 [파이프라인 검증]을 통해서 구성이 유효한지 여부를 확인할 수 있습니다.

아래는 작성해야 하는 필수값과 그에 대한 설명입니다. (디테일한 설정은 주석의 REQUIRED를 참고해주세요.)
version: "2"
dynamodb-pipeline:
source:
dynamodb:
acknowledgments: true
tables:
# DynamoDB 테이블 ARN 입력
- table_arn: "<<arn:aws:dynamodb:us-east-1:123456789012:table/MyTable>>"
stream:
start_position: "LATEST"
export:
# 생성한 S3 버킷명
s3_bucket: "<<my-bucket>>"
# S3 버킷의 리전
s3_region: "<<us-east-1>>"
s3_prefix: "ddb-to-opensearch-export/"
aws:
# 생성한 IAM 역할(dynamodb, s3 액세스 권한)
sts_role_arn: "<<arn:aws:iam::123456789012:role/Example-Role>>"
# AWS 계정 리전
region: "<<us-east-1>>"
sink:
- opensearch:
# OpenSearch 도메인 엔드포인트(IPv4)
hosts: [ "<<https://search-mydomain-1a2a3a4a5a6a7a8a9a0a9a8a7a.us-east-1.es.amazonaws.com>>" ]
index: "table-index"
index_type: custom
document_id: "${getMetadata(\"primary_key\")}"
action: "${getMetadata(\"opensearch_action\")}"
document_version: "${getMetadata(\"document_version\")}"
document_version_type: "external"
aws:
# IAM 역할(도메인에 대한 액세스 권한)
sts_role_arn: "<<arn:aws:iam::123456789012:role/Example-Role>>"
# 생성한 도메인 리전
region: "<<us-east-1>>"
serverless: false
# S3 DLQ를 활성화하여 실패한 요청을 캡처
dlq:
s3:
# S3 버킷명
bucket: "<<your-dlq-bucket-name>>"
# 버킷 리전
region: "<<us-east-1>>"
# S3 액세스 권한이 부여된 IAM 역할
sts_role_arn: "<<arn:aws:iam::123456789012:role/Example-Role>>"3. (참고) 파이프라인의 상태가 활성화되고 데이터 수집을 시작하면 S3 버킷에 ddb-to-opensearch-export 접두사 폴더를 생성한 것을 확인할 수 있습니다.

4. OpenSearch 대시보드를 통해 데이터 쿼리
1. 생성한 파이프라인의 OpenSearch 대시보드 URL로 접속합니다.

2. OpenSearch의 파이프라인을 구성할 때 ProductCatalog 테이블을 table-index라는 인덱스로 설정했습니다. OpenSearch 대시보드의 Dev Tool 화면에서 이 인덱스 테이블로 GET 요청을 보내면 “Geroge Orwell”이라는 “저자” 필드와 일치하는 데이터를 반환하는 것을 확인할 수 있습니다.

마무리
실습동안에 발생한 OpenSearch 서버리스의 비용을 고려하면 데이터 규모가 상당히 커야 비용 효율적인 솔루션을 사용할 수 있을 것 같다는 생각이 들었습니다.
다만, 이번 포스팅에서는 2023년 11월에 출시된 Zero-ETL 기능을 어떻게 구축하는지 알아보았고, 불필요한 데이터 처리 과정 없이 데이터 인사이트를 도출할 수 있기 때문에 이 기능을 통해 새로운 Use case 들이 만들어질 수 있을 것 같습니다.



Comments